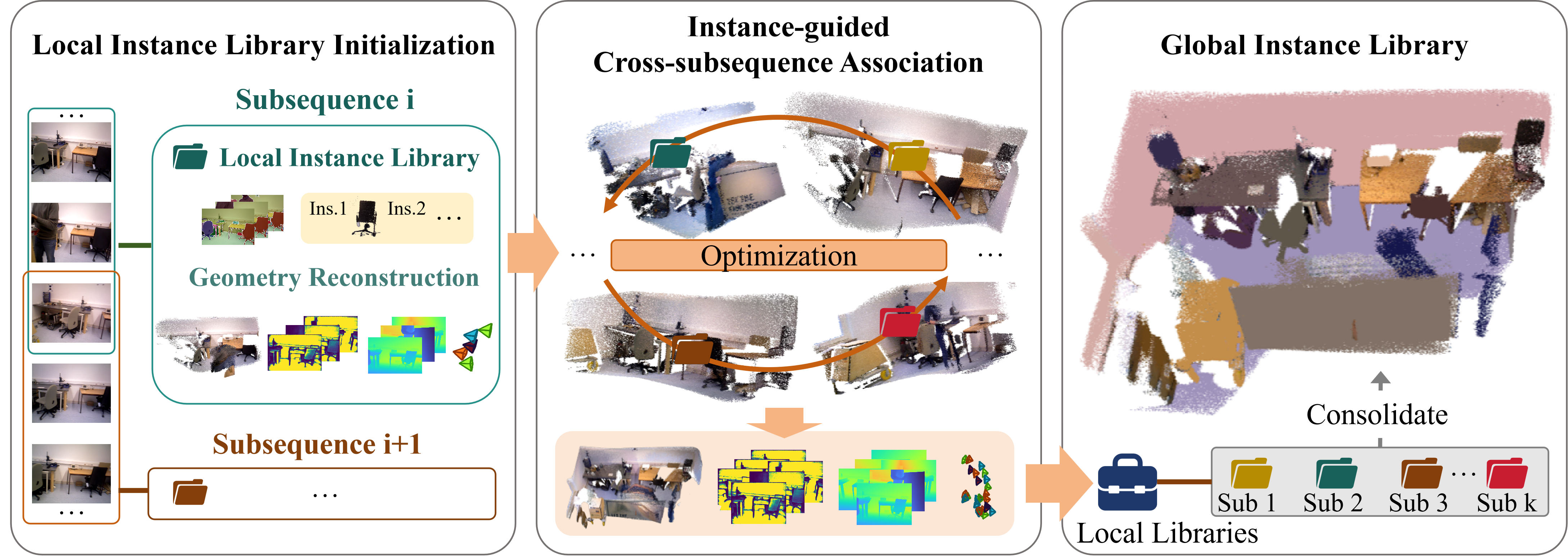
Overview
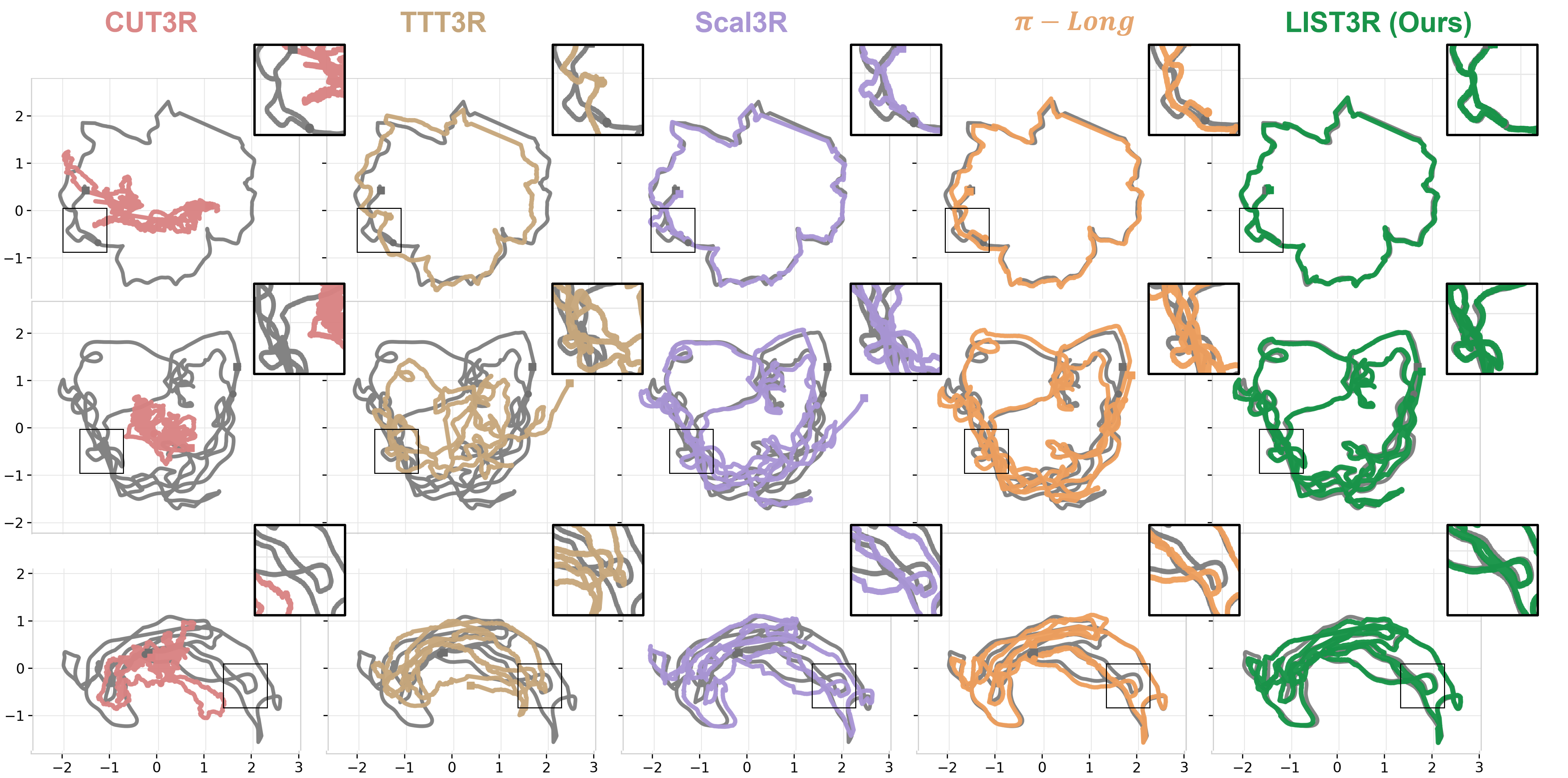
We present LIST3R, an instance-aware framework for long-sequence 3D reconstruction inspired by the way humans organize spatial memory around stable and recognizable objects. LIST3R organizes long-sequence reconstruction around instance anchors, using them to reconnect fragmented subsequences and consolidate local observations into a coherent global 3D scene. Given a long video, our approach partitions it into overlapping subsequences and builds a local instance library for each partial reconstruction, maintaining trackable anchors with semantic and geometric evidence. These anchors are matched across subsequences to recover revisited regions and provide object-aware constraints for fragment alignment, producing a global reconstruction. During this process, the evolving geometric evidence updates the local instance libraries and progressively organizes them into a unified global 3D instance library. Experiments on long-sequence benchmarks show that our method produces more accurate trajectories and higher-quality 3D reconstructions, highlighting the effectiveness of persistent instance anchors for organizing long-horizon 3D reconstruction.